인코딩(Encoding)
레이블(Label) 인코딩
카테고리 피쳐를 코드형 숫자 값으로 변환
ex)
"북미" -> 0
"남미" -> 1
"아시아" -> 2
- 주의사항
"북미" 가 0이고, "아시아" 가 2로 변환되어 0 < 2 이므로, "아시아" 가 "북미" 보다 더 중요한 값으로 해석될 수 있다.
따라서 회귀 계열의 ML 알고리즘에서는 사용할 수 없고, 분류 계열의 알고리즘에서는 사용해도 문제없다.
원-핫 인코딩
여러 개 속성 중에서 하나의 속성만 1 로 표시한다고 하여 원-핫 인코딩

가령 라면은 [1,0,0,0,0] 의 값으로 표현된다.
#import pandas as pd
df = pd.DataFrame({'item': ['TV', '데스크탑', '선풍기', '에어컨', '에어프라이기', '제습기', '공기청정기', '가습기', '청소기']})
df_oh = pd.get_dummies(df)
df_oh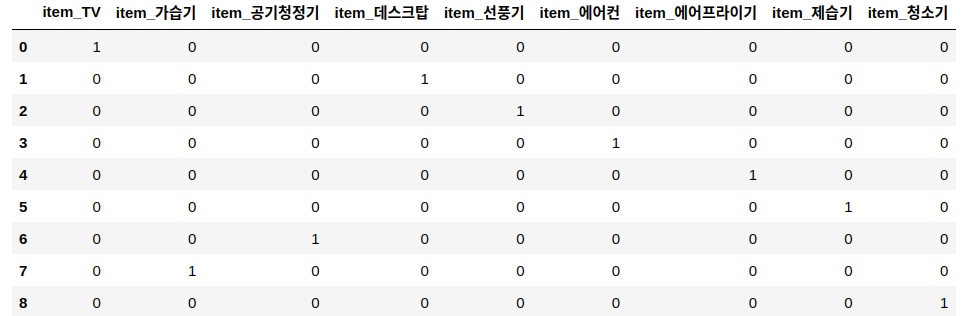
피쳐 스케일링(feature scaling)
서로 다른 변수들의 값 범위를 일정한 수준으로 맞추는 작업.
변수들 값 범위를 맞춰줌으로써 다른 변수들을 비교할 수 있게 된다. (키와 - cm 몸무게 - kg 을 비교한다던지)
> 표준화(Standardization)
정규 분포를 따르는 데이터를 평균이 0, 분산이 1인 가우시안 정규 분포화하는 작업

μ 는 정규분포를 따르는 데이터 집합 X 의 평균이고 𝞼는 X의 표준편차이다
정규분포의 성질에 따라 Z는 평균이 0이고 분산이 1인 변수가 된다.
from sklearn.datasets import load_iris
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data = iris_data, columns = iris.feature_names)
print(iris_df.head())
print(iris_df.mean())
print(iris_df.var())
# Standard Scale
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
print(type(iris_scaled))
iris_df_scaled = pd.DataFrame(iris_scaled, columns=iris_df.columns)
print(iris_df_scaled.mean())
print(iris_df_scaled.var())
iris_df_scaled
각 피쳐값들의 평균값이 거의 0 이 되었고, 분산도 거의 1이 되었다.
위의 표준화 된 뒤의 데이터셋 테이블을 보면 피쳐들 단위가 cm 인데 사실 귀찮아서 그대로 둔 것뿐이고,
표준화를 거친 새 변수값들이기 때문에 cm 이라는 단위는 사라졌다고 보는 게 맞다.
> 정규화(Normalization)
변수들을 최소 0 ~ 최대 1의 범위의 값으로 통일
0 ~ 100,000,000 범위의 데이터도, 0~100 의 데이터도 모두 최소 0~ 최대 1의 범위로 변환하는 셈
정규화 방법 중에 Min-Max feature scaling 방식이 있다.

# min_max scale
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import load_iris
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data = iris_data, columns = iris.feature_names)
scaler = MinMaxScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(data = iris_scaled, columns = iris.feature_names)
print("## 평균 편차")
print(iris_df_scaled.mean())
print(iris_df_scaled.var())
print("## 최솟값 최댓값")
print(iris_df_scaled.min())
print(iris_df_scaled.max())
iris_df_scaled.head()
'Study > Machine Learning 개론' 카테고리의 다른 글
| 4. ROC curve 와 AUC (0) | 2023.09.17 |
|---|---|
| 3. Confusion matrix(오차행렬) 와 정밀도, 재현율, F1 score (1) | 2023.09.08 |
| 1. 교차 검증 (0) | 2023.09.04 |


